UCLA Synthetic Data Workshop


April 13th - 14th, 2023
We are pleased to announce the UCLA synthetic data workshop. This two-day workshop is hosted by the UCLA Department of Statistics and co-sponsored by IDRE, Science Hub for Humanity and Artificial Intelligence, ASA Section on Statistical Computing, NISS and NSF. The workshop is held at the UCLA Faculty Club, Morrison Room from April 13-14, 2023.
About
Synthetic data generation is an interdisciplinary field that is rapidly gaining momentum in both academia and industry. Synthetic data has become a valuable resource for the development of algorithmic procedures, fraud detection, spam identification, and the construction of AI-driven models in industries such as manufacturing and supply chain management. The benefits of synthetic data include cost savings, increased speed and agility, advanced intelligence, and state-of-the-art privacy. The Gartner report forecasts that synthetic data will largely replace real data for training machine/deep learning models by 2030, as depicted in the figure below. Additionally, synthetic data was named one of the top 10 game-changing innovations for 2022 by the MIT Technology Review. Synthetic data comes in various forms, such as image, text, graph, and tabular data, and has different names, such as simulated data, missing value imputation, and GAN, depending on the scientific community. Synthetic data generation is expected to become an essential component of next-generation machine learning workflows.
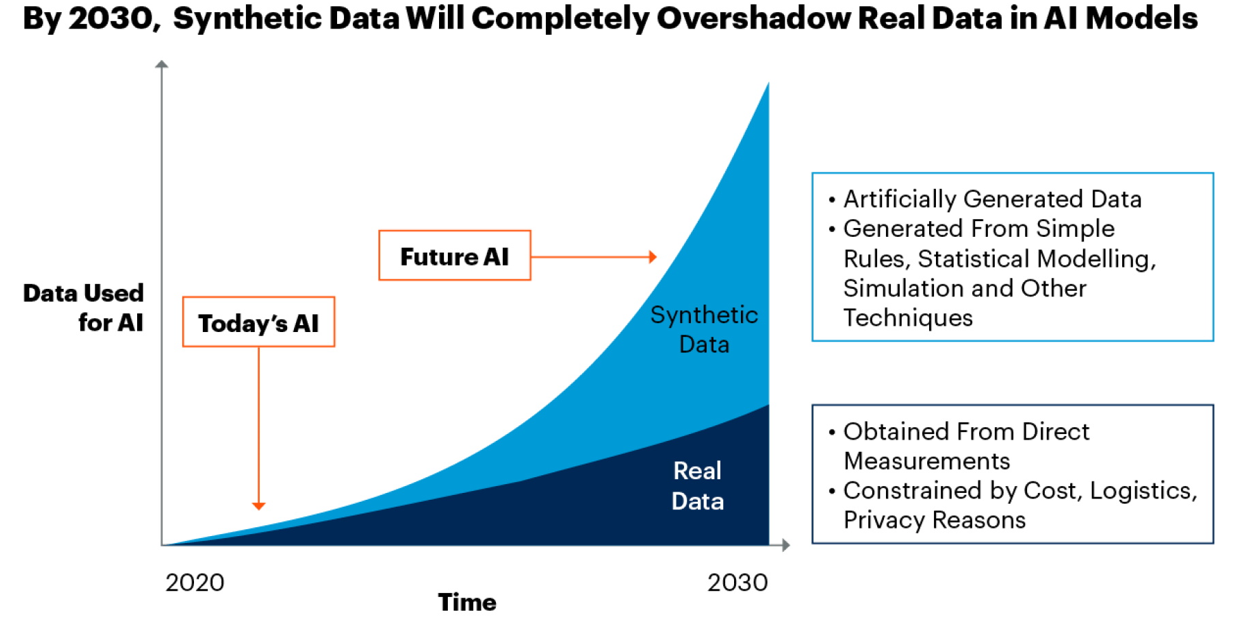
Despite the numerous successful applications of synthetic data, its scientific foundation, such as the tradeoff among fidelity, utility, and privacy, is still underdeveloped. Moreover, industrial standards for generating and utilizing synthetic data are not yet fully developed. Additionally, the privacy law on synthetic data is still in its infancy. Therefore, the purpose of this workshop is to bring together a community of synthetic data researchers from statistics, machine learning, and mathematics, policymakers, and industrial partners to collaborate on developing the theory, methodology, and algorithms necessary for producing synthetic benchmark datasets and algorithms.
Program
All events will be held at UCLA faculty club, Morrison Room.
Day 1: April 13, Thursday
- 8-8:50 Breakfast & Register
- 8:50-9 Opening Remark
- 9-9:40 Keynote Talk by Xiao-Li Meng, Harvard Statistics
Title: Data Minding for Synthetic Data: Have We Ever Had Real Data?
Chair: Ying Nian Wu, UCLA Statistics
Slides: CLICK HERE - 9:40-10 Coffee/Tea
- 10-11:30 Invited Session 1: Synthetic Data for Social Science
Session Chair: Andrés Felipe Barrientos, FSU Statistics
- Title: Stylized Facts about Synthetic Data for the Social Sciences – an illustration using data from the U.S. Economic Census
Speaker: Joerg Drechsler, IAB in Germany
Slides: CLICK HERE - Title: New Methods and Applications in Synthetic Data for Survey Data
Speaker: Joshua Snoke, RAND - Title: Synthesizing Tax Data with Tidy-synthesis
Speaker: Aaron Williams, Urban Institute
Slides: CLICK HERE
- Title: Stylized Facts about Synthetic Data for the Social Sciences – an illustration using data from the U.S. Economic Census
- 11:30-11:50 Coffee/Tea
- 11:50-12:30 Legal Panel
Moderator: Mark Mckenna, UCLA School of Law
- 12:30-13:30 Lunch
- 13:30-13:50 Group Picture
- 13:50-14:30 Keynote Talk by Aloni Cohen, UChicago Computer Science
Title: Deidentification and Data Deletion — A Cryptographer’s Take
Chair: Mark Mckenna, UCLA School of Law - 14:30-15:00 Coffee/Tea
- 15:00-16:30 Invited Session 2: Trustworthiness of Synthetic Data
Session Chair: Shirong Xu, UCLA Statistics
- Title: Differentially Private Synthetic Data Can Be Accessible and Equitable
Speaker: Lucas Rosenblatt, NYU Center for Responsible AI - Title: Generative AI in Healthcare: Synthetic Patient Records and Clinical Trial Optimization
Speaker: Jimeng Sun, UIUC Computer Science - Title: The Duality of Private Synthetic Data and Reconstruction Attacks
Speaker: Steven Wu, CMU Computer Science
Slides: CLICK HERE
- Title: Differentially Private Synthetic Data Can Be Accessible and Equitable
Day 2: April 14, Friday
- 8-9 Breakfast & Register
- 9-9:40 Keynote Talk by Kalyan Veeramachaneni, MIT LIDS, DataCebo
Title: The Synthetic Data Vault: A Decade Long Journey to Build Algorithms, Systems and User Base
Chair: Guang Cheng, UCLA Statistics - 9:40-10 Coffee/Tea
- 10:00-11:00 Industrial Panel
Moderator: Belinda Zeng, Amazon
- 11:00-11:20 Coffee/Tea
- 11:20-12:50 Invited Session 3: Generative Models for Text/Image Data
Session Chair: Ying Nian Wu, UCLA Statistics
- Title: Leveraging Synthetic Data for Machine Unlearning
Speaker: Alessandro Achille, Amazon - Title: Controllable Text Generation Beyond Auto-Regressive Models
Speaker: Nanyun Peng, UCLA Computer Science - Title: Recreating Diverse Traffic Scenarios for Benchmarking Embodied AI Safety in Simulation
Speaker: Bolei Zhou, UCLA Computer Science
Slides: CLICK HERE
- Title: Leveraging Synthetic Data for Machine Unlearning
- 12:50-13:50 Lunch
- 13:50-14:30 Keynote Talk by Roman Vershynin, UCI Mathematics
Titile: Mathematical Foundations of Private Synthetic Data
Chair: Guang Lin, Purdue Math
Slides: CLICK HERE - 14:30-15:00 Coffee/Tea
- 15:00-16:30 Invited Session 4: Structured Synthetic Data (Tabular and Time Series)
Session Chair: Chi-hua Wang, UCLA Statistics
- Title: Marginal-based Methods for Differentially Private Synthetic Data
Speaker: Ryan McKenna, Google - Title: Task-Agnostic Benchmarking of Pretrained Representations Using Synthetic Data
Speaker: Ching-Yun (Irene) Ko, MIT EECS
Slides: CLICK HERE - Title: Continuous Conditional GANs with Generator Regularization
Speaker: Yunkai Zhang, UCB IEOR
Slides: CLICK HERE
- Title: Marginal-based Methods for Differentially Private Synthetic Data
Poster
It is strongly encouraged to upload your poster in the registration link below (deadline is April 1st). You need to bring posters to the conference site to setup. The poster exhibit time is from 9:40-3:00 either Thursday or Friday.
Travel Support
Travel support is available for junior participants (who received PhD degree after 2018), invited speakers and panel discussants. Registration fee will be reimbursed for participants that receive travel support.
Registration (Deadline April 1st, 2023).
CLICK HERE to register for the April 13th - 14th, 2023 UCLA synthetic data workshop.
CLICK HERE to pay the registration fee.
PLEASE NOTE: Submitting the above Google form DOES NOT guarantee a place in the workshop until the registration fee is paid.
Accommodation
If you need accommodation, nearby options include the following local hotels.
- UCLA Meyer & Renee Luskin Conference Center
- UCLA Guest House
- Palihotel Westwood Village
- Royal Palace Westwood
- W Los Angeles Westwood
Organizers
- Guang Cheng, UCLA Statistics (Chair)
- Xiaowu Dai, UCLA Statistics
- Mark Mckenna, UCLA School of Law
- Jerry Reiter, Duke Statistics
- Ying Nian Wu, UCLA Statistics
- Hongquan Xu, UCLA Statistics
Contact
For more information contact Prof. Guang Cheng.